RDMAをEthernet上で実現する仕組みであるRoCE v2についてマイクロソフト社内での運用 1 について調べてみた。
イントロ
RDMAというとInfinibandというイメージだったが、最近はiWARP、RoCEなども候補になる。 RoCEを略さずにいうと、Remote Direct Memory Access over Converged Ethernetとなる。 Remote Direct Memory Access とは、CPUを経由せずにリモートノードの主記憶を読み書きできる仕組みである。Converged Ethernet とはロスレスなEthernetであると理解した。 RoCEは2種類のバージョン v1 と v2 がある。v1はL2ヘッダの後ろにRDMAのペイロードが置かれる構造をしている。原理的にL2サブネット間でのRDMAを想定している。一方、v2はL4ヘッダの後ろにRDMAのペイロードが置かれる。つまり、Ethernet/IP/UDP上のプロトコルなので、IPルーティングを経由したRDMAを実現できる。
そもそもなぜデータセンター内でRDMAが必要になるからというと、TCP/IPスタックで満たせない需要が出てきたからだと思う。例えば、40Gbps・8セッションの通信におけるCPUの利用率をみると、送信側で8%、受信側で12%となる。このオーバヘッドの削減がRDMA導入の狙いとなる。遅延の削減も狙いとなることが多い。エンドノードのネットワークスタックがソフトウェア実装(Linuxカーネルなど)であるため、原理的に遅延が入り込む余地(スケジューリング待ちなど)がある。また、TCP/IPはパケットドロップの発生を前提とした輻輳制御を行うので、ここも遅延の原因となる。
今回はIP CLOS ネットワーク上で RDMA を実現する。ほぼ全てのリンクが40Gで、全てのスイッチがIPルーティングを担当する。 RoCE v2は5-tupleを持つので、ECMP(Equal Cost Multipath Routing)の恩恵を受けられる。 ロスレスネットワークでは、通信経路中のスイッチで、バッファオーバーフローなどによるパケロスが起きてはならない。 そこで、PFC(Priority-based Flow Control)を使って、流量を制御する。 PFCは、リンク間のプロトコルで、スイッチのバッファ利用率がある閾値を超えると、リンク相手のスイッチに対して pause frame を送出する。 pause frame はパケットの送出停止を依頼する意味を持つ。 キューごとに Priority を割り当てられるので、キューの単位でpause frameを送ることができる。 ただ、pause frame を送ってから、実際の送信が停止されるまでには、時間差があるので、余裕を持たせておく。 マイクルソフト社内では、スイッチがShallow Bufferなので、2つのPrirorityのみを使っている。 片方が遅延を重視するリアルタイムトラフィック用途、もう一方が帯域を重視するバルクデータトラフィック用途に使われる。 PFCはリンク間のプロトコルなので、RDMAのエンドノードに到達するまでに何度かスイッチを伝播する。 そこで、エンド間のプロトコルであるDCQDN(Data Center Quantized Congestion Notification)と組み合わせて使っている。
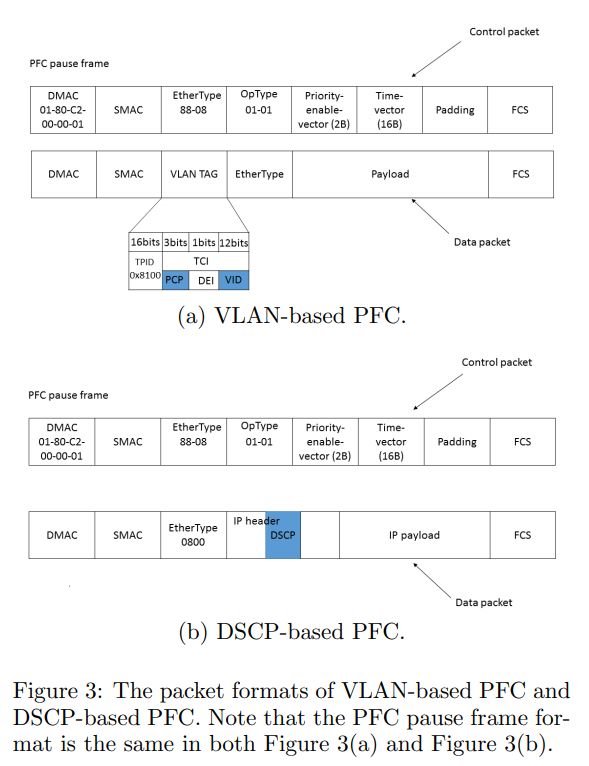
PFCプロトコルには、Priorityをどのヘッダに設定するかによって、2種類の仕様が存在する。もともとはVLANタグの中にPriorityを設定するVLAN-basedな仕様だった。ただ、IPルーティングを前提とするIP CLOSネットワークや、PXEブートとの相性が良くなかった。そこで、IPヘッダのDSCPにPriorityを設定するDSCP-basedな仕様が出てきた。マイクロソフト社内では、単純にPFC PriorityをDSCPの値として割り当てている。現在では主要なスイッチベンダがDSCP-basedをサポートしている。
課題
ロスレスなネットワークであってもパケロスを完全に防ぐことはできない。例としてFCS(Frame Check Sequence)やソフトウェアバグが原因となる。実験として0.4%(1/256)の確率でパケロスを起こしてみると、リンクではワイアーレート出ているが、アプリケーションからみると全く進捗がなかった。これは、あるパケットがドロップされると、先頭のパケットから再送されるという仕様によるものだった。対策としてドロップを検知したパケットから再送する(go-back-N)ように変更した。
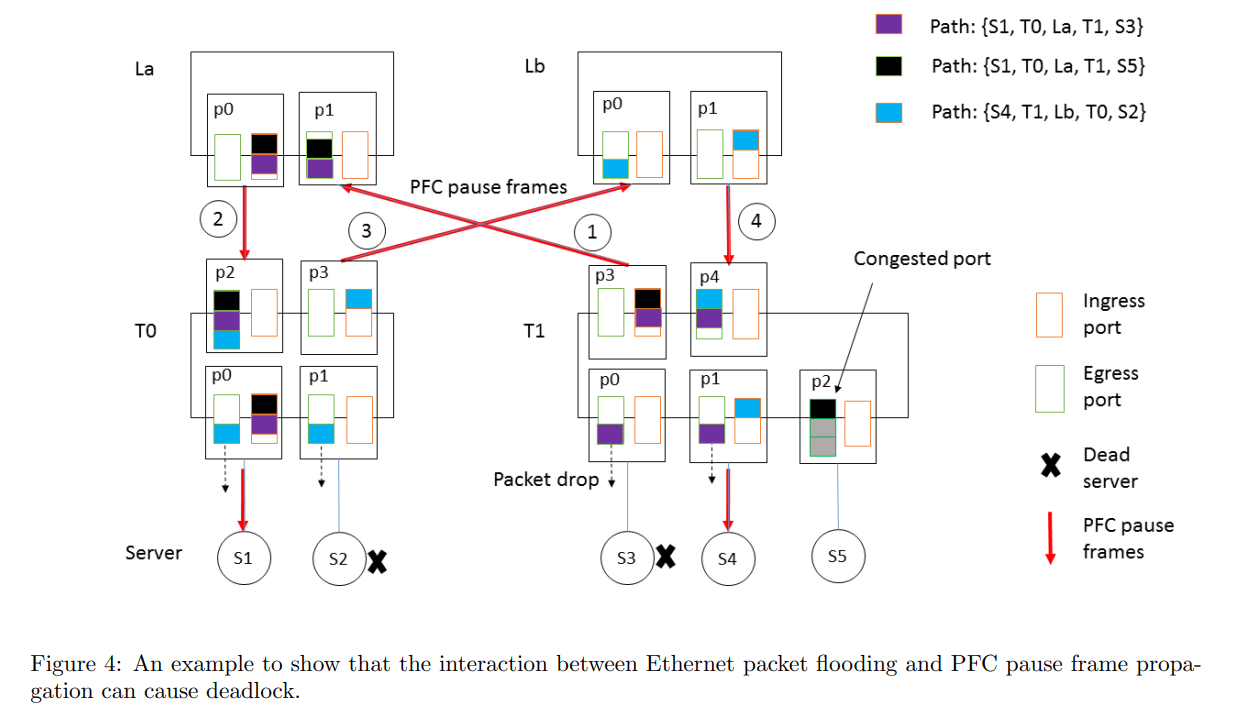
CLOSトポロジでは、パケットはToR-Leaf-Spine-Leaf-ToRという経路を辿るため、バッファの循環依存はなく、デッドロックは原理的に発生しないだろうと想定していた。ここで、バッファの循環依存とは、全てのバッファが飽和していて、かつそれらが相互に依存しているとき、どのバッファもデータを送り出せなくなってしまうこと。前提として、ToRの配下のサーバは同一サブネットに属している。また、ToRはパケットを受信すると、ARP tableとMAC address tableを参照する。ARP tableはCPU処理なのでキャッシュ期間が4時間であり、MAC address tableはハードウェア処理なのでキャッシュ期間が5分となっていることに注意する。このキャッシュ期間の差分が循環依存の原因となる。ARP tableにエントリが存在するが、一方でMAC address tableにエントリが存在しない場合、ユニキャストフラッディングによりパケットは受信ポート以外の全てのポートから送出される。つまり、ToR-Leaf-Spine-Leaf-ToRといった経路の前提が崩れてしまい、循環が発生してしまう。さらに、PFCと組み合わさせることにより、デッドロックに陥ってしまう。対策として、ロスレスネットワークでは、フラッディングの代わりにドロップさせた。ロスレスネットワークにおけるブロードキャストやマルチキャストの利用は危険なので注意する。
NICの受信キューにバグがあり、PFC pause frame を送出し続ける状況があった。PFC pause frameはネットワーク全体に波及するため、影響範囲が大きい。そこで、NICとToRにウォッチドッグを実装した。
Server・ToR間が40Gbps、Server内PCIe Gen3 x8は64Gbpsなので、サーバ内で輻輳は発生しないと想定していた。しかし、NIC内のMTT(Memory Transaction Table)のエントリ数不足が原因で、NIC・主記憶間でアクセスが発生し、その遅延によりバッファが溜まってしまった。ページサイズを増やして対応した。
運用
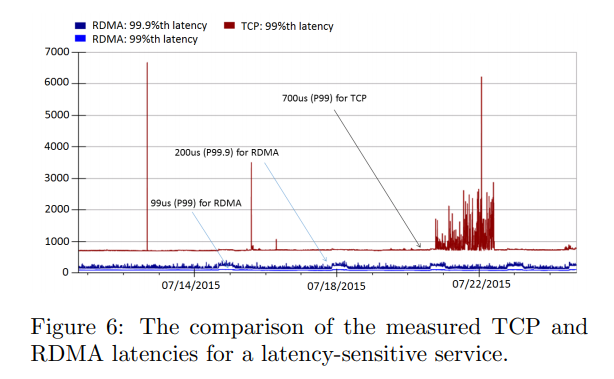
スイッチごとに送受信したPFC pause frameの数を集計している。サーバごと pause した期間をスイッチから取得したがったが、現状できないので、ベンダと調整している。 継続的な遅延の計測を目的として、RDMA Pingmeshを導入した。異なる場所に配置したサーバに対して、512バイトのデータをRDMAで転送して、RTTやfailureの理由を計測している。 実際に低スループットな状況で遅延をみてみると、TCP環境と比較して、低遅延であった。99.9パーセンタイルで見てもバースト的な遅延は発生しなかった。 ただ、高スループットを出した場合には、遅延がTCP環境程度にまで落ち込んでしまう。 つまり、RDMAは高スループットと低遅延を同時に満たすものではない。
まとめ
RoCE v2をデータセンターに大規模にデプロイした。また、DSCPベースのPFCを提案した。今後は、データセンター間RDMA、Multi-path TCPやPer-Packet RoutingのアイデアへのRDMAに応用に取り組みたい。