NSDI 2021 でのFacebookの論文 1 を読んでみて、間違いをおそれず自分の言葉でまとめてみる。
概要
FacebookのBGPをベースとしたデーターセンターネットワークについてまとめもの。AS番号の割り当て、経路集約、BGPポリシー、独自のBGP実装に対するテストやデプロイ手法など実践的な内容となっている。終盤には実際に過去2年間の運用において経験した事故についても触れられている。
1 イントロ
Facebookはいくつかのデータセンターを展開しているが、それらのデータセンターでは共通するAS番号の割り当てスキーマを持っている。つまり、データセンターAのスイッチに相当するデータセンターBのスイッチも同じプライベートAS番号を持つことになる。大量のスイッチでBGPエージェントを動かし全体として階層的な構造を持つClosトポロジーを採用しているが、その全てのレイヤで経路集約を行っており、ハードウェアのFIBを最小限に保っている。BGPはもともとインターネットで使われていた技術で、その歴史の中で収束上の問題、経路の不安定さ、設定ミスによる事故を経験してきたが、データセンターに応用する場合には運用者が全てのスイッチを管理・運用できるため、これらの問題に柔軟に対応することができる。例えば、通信障害に対しては、事前にバックアップ経路を入れておくことで、例えリンクあるいはスイッチに障害が発生したとしても、その障害を伝播させる範囲を限定することで、、迅速に収束させることができる。さらに、ベンダ製BGPエージェントよりも高速な開発スパンを持つミニマムな実装を目指して、Facebook社内で独自にBGPエージェントを開発している。
2 ルーティング設計
スケールするネットワークの構築が目的だが、同時に短期間に構築する必要がある。また、どんなに可用性を追求しようとも事故は起きるので、その影響範囲を設計として縮小したい。当時、中央集権のSDNを開発することに比べ、BGPを使ったルーティング設計を展開する方がスピードと実績の両面で優位にあった。もともとベンダ製スイッチとそのBGP実装を使っていたが、後に独自にハードウェアとBGPエージェント実装を行うようになった。
ルーティングプロトコルとしてOSPFやISISのようなIGPも検討したが、スケール性能が不透明で経路の伝播を制御できそうになった。BGPとIGPを組み合わせたハイブリットなルーティング設計も考えたが運用コストが高くなるので、最終的にBGPを唯一のルーティングプロトコルとして採用することにした。
2.1 トポロジ設計
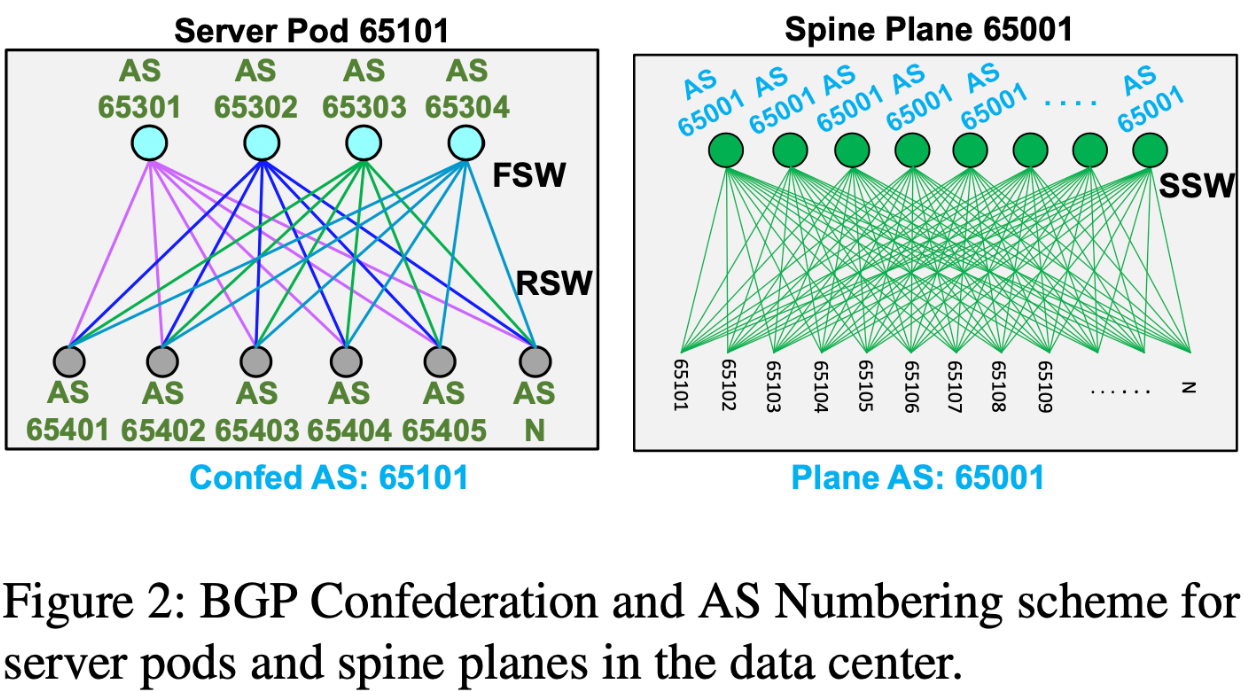
サーバポッドと呼ばれるラックの集合をモジュールとしてまとめ、それをSpine Planeがまとめ上げる形でデータセンターを設計する。トポロジについては下図から読み取れるが、ここでは言葉でも書いておく。1つのサーバポッドは48個のサーバラックから構成され、16個のFSWに接続される。サーバポッド間は、複数のSpine Planeを経由することで、相互に接続される。Spine Plane自体の数は、1つのサーバポッドの中に展開されるFSWの数と等しい(下図では青黄緑紫の4つ)。Spine Planeとサーバポッド間でリンクを増やすことによって帯域を増大できる。つまり、サーバポッドの追加によってコンピュートリソースを、SSWの追加によってネットワークリソースを増大できる。
 出典:
出典: 2.2 ルーティング設計の指針
同一性と単純さを求めるというのが2つの大きな柱となる。これらを達成するために、BGPで利用するFeature Setを最小限にし、複数のスイッチへできるだけ同一の設定を適用しようと取り組んでいる。同じTier(RSW、FSW、SWW)の中では、OriginateするプレフィックスやBGPピアアドレスを除いて、同じ設定を投入している。また、ベンダ依存を取り払うために、特定のプラットフォームに依存しない形で、ネットワークトポロジデータを作っている。このデータには、ポートマップ、IPアドレス割り当て、BGPの設定、ルーティングポリシーが含まれる。Robotron 2 と呼ばれるシステムによって自動的にプラットフォームごとの設定へと変換している。
2.3 BGPピアリングと負荷分散
ピアリングは直接繋がれた1ホップのeBGPセッションでのみ行う。マルチホップは使わない。スイッチに複数のリンクがあった場合には、それぞれ個別のeBGPセッションとして扱う。負荷分散はECMPによって実現する。後述する経路集約やルーティングポリシーの仕組みによって、障害発生時・復旧時に発生するネクストホップの追加・削除に伴うFIBの更新は軽量で、運用は簡潔になった。単純さを理由に、経路ごとの重み付けは行なっていない。
2.4 AS割り当て
AS割り当ては全てのデータセンターで同一である。例えば、あるデータセンターで1つ目のSSWにAS65001を割り当てたとすると、別のデータセンターでも同じAS番号が再利用される。サーバポッドには、それ自身を示すAS番号が割り当てられ、そのサーバポッドの外からはこのAS番号によって識別される。つまり、サーバポッド内のスイッチ(RSW、FSW)のAS番号はそのサーバポッド内に閉じることになる。この性質から、RSWとFSWのAS番号は全てのサーバポッドで再利用される。Spine Planeにはデータセンター内でユニークなAS番号が割り当てられる。Spine Planeは複数のSSWから構成されるが、それらSSWは同一のAS番号を持つ(SSW間でピアを張ることはないので共通化できる)。
 出典:
出典: 2.5 経路集約
階層的に全てのTierにおいて、経路集約を行なっている。例えば、RSWは配下のサーバのIPを集約し、FSWは配下のRSWの経路を集約する。経路集約によって、数十万経路から数千経路へと大幅に削減できる。
3 ルーティングポリシー
BGPを使うことで、ベストパス選択による高可用性の恩恵を受けることができる。さらに、経路広報に介入できることから、伝播を高精度に操作できる。
3.1 ポリシーのゴール
信頼性、保守性、スケーラビリティ、サービス到達性の4項目を達成したい。
- 信頼性
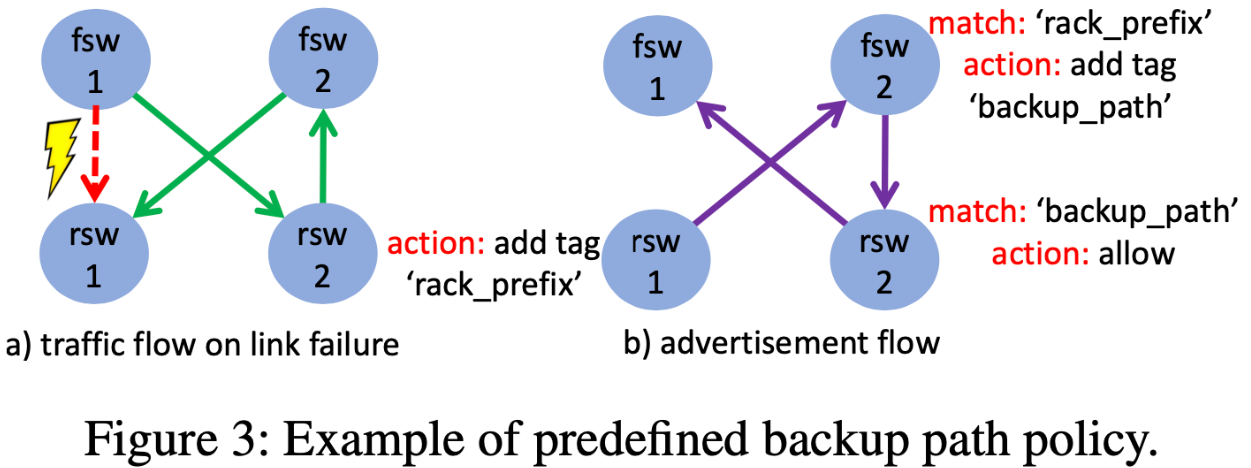
- 経路伝播のスコープを制限し、事前にバックアップ経路を定義していく。バックアップ経路はFSW1->RSW2->FSW2->RSW1のようなもので、BGPコミュニティタグをつけた上で、あらかじめサーバポッドに閉じたスコープで伝播させておく。バックアップ経路があることで、あるリンクがダウンしても、サービスを継続できる。伝播がサーバポッドに閉じるという性質から、収束までの時間が短く、別のサーバポッドへの影響がない。また、実際にはバックアップ経路はECMPによって複数存在することになるので負荷は分散される。
- 保守性
- スイッチにはアップ・ダウンのような2種類の状態ではなく、LIVE・DRAINED・WARMという3種類の状態を持つ。WARMはRIBやFIBが準備完了だが、トラフィックは流れていない状態に対応する。この3状態を持つことで、一日あたり平均242回のオペレーションを行なっているが、パケットドロップは発生していない。
- スケーラビリティ
- FSWではラックレベルのプレフィックスを集約するため、サーバポッド追加による経路数の増加が小さくスケールする。
- サービス到達性
- サービスはVIPを経由して提供され、そのVIPは複数のインスタンスからBGPによって広報される。広報のため、インスタンスはRSWに対して直接BGPセッションを張っている。
 出典:
出典: 3.2 ポリシー設定
インバウンドで3~11個、アウトバウンドで1~23個のポリシーを投入している。
3.3 ポリシーの変更
過去3年間でわずか40コミットだけの変更で非常に安定している。内訳としては、80%以上のコミットは、全行数の2%以下を変更するという小規模なものであった。
4 データセンターとインターネットにおけるBGPの比較
BGPの収束、不安定さ、設定ミスについてはインターネットの文脈で長く議論されてきた。ここではデータセンターでの文脈でまとめる。
4.1 BGPの収束
インターネットではBGPの収束に数分かかることが知られている(Path Hunting問題)。また、最悪のケースではルータ数をnとするとO(n!)個のメッセージが流れることになる。データセンターでは、BGPの広報する範囲を限定することで、メッセージ量を大幅に削減できる。メッセージの送信間隔を制御するMIRAIタイマーは0秒として、できるだけ早い収束を目指す。
4.2 経路の不安定さ
大量のBGP Updateメッセージが送られることによって、ルータのCPUやメモリが枯渇し、収束が遅くなったりパケロスしたりということに陥る。不安定さの原因としてWWDup、AADup、AADiff、Tup/TPown(要復習)が挙げられる。
 出典:
出典: 4.3 BGPの設定ミス
Originateするプレフィックスの間違い、AS_PATHの間違いという2つのミスが発生しうるが、自動化ツールと監視によって防いでいる。
5 ソフトウェア実装
既存BGP実装に新機能を追加するのは難しく、開発サイクルも長いため、Facebookでのデータセンターでの適用には向かなかった。そこで、C++でFBOSSスイッチ上で動くBGPエージェントを自分たちで開発した。RFCを満たしつつ、データセンター内での利用に限定した必要最小限の実装を行なった。マルチスレッドに対応させた(QuaggaやBirdはシングルスレッド)ことで、収束にかかる時間はQuaggaやBirdの1.7~2.3倍短縮された。
ベンダのBGP実装は、同一のピアアドレスから複数のBGPセッションを貼ることができず、アプリケーションのためのVIPを広報するのに難儀した。 そこで、この制約を取り払い、アプリケーションが直接RSWへとBGPセッションを貼ることができるようにした。 サーバ内のInjectorを介入しないので、オペレーションコストが削減された。
6 テストとデプロイ
テストやデプロイの対象は、BGPの設定とエージェント自体の実装の2つ。
6.1 テスト
テストは、大きく分けてユニットテスト、エミュレーション、カナリアテストから構成される。エミュレーションは非常に便利なツールで、BGP設定やポリシーを踏まえて、ネットワーク全体を模倣してテストしている。また、リンクフラップ、リンクダウン、BGPリスタートなどのイベントを模倣するのにも役立つ。ただLinuxコンテナ上のエミュレーションはハードウェアスイッチと比べて遅いため、BGPの収束時間を実験すること自体が挑戦的なトピックになった。
6.2 デプロイ
徐々に更新していくローリングアップデートを採用しつつ、問題があれば早期に検出したい。まず、全ての変更を、パケット転送の状態を変更するか否かという指標で、破壊的・非破壊的のどちらかに分類する。非破壊的な場合には、BGP Gracefull Updateのしくみを使って経路をそのままにデプロイする。一方、破壊的な変更の場合には、経路の追加・削除や、BGPの再収束が必要になるため、一旦スイッチをDrainしてデプロイする。適用範囲を6段階に分け、徐々にデプロイを進め、最終的にデータセンター全体を更新する。全てのBGPエージェントは、BGPMonitorというサービスに受け取ったメッセージを転送する仕組みを持っている。このBGPMonitorによって、非破壊的な変更が起因して不正なメッセージが送られていないか検知できる。
 出典:
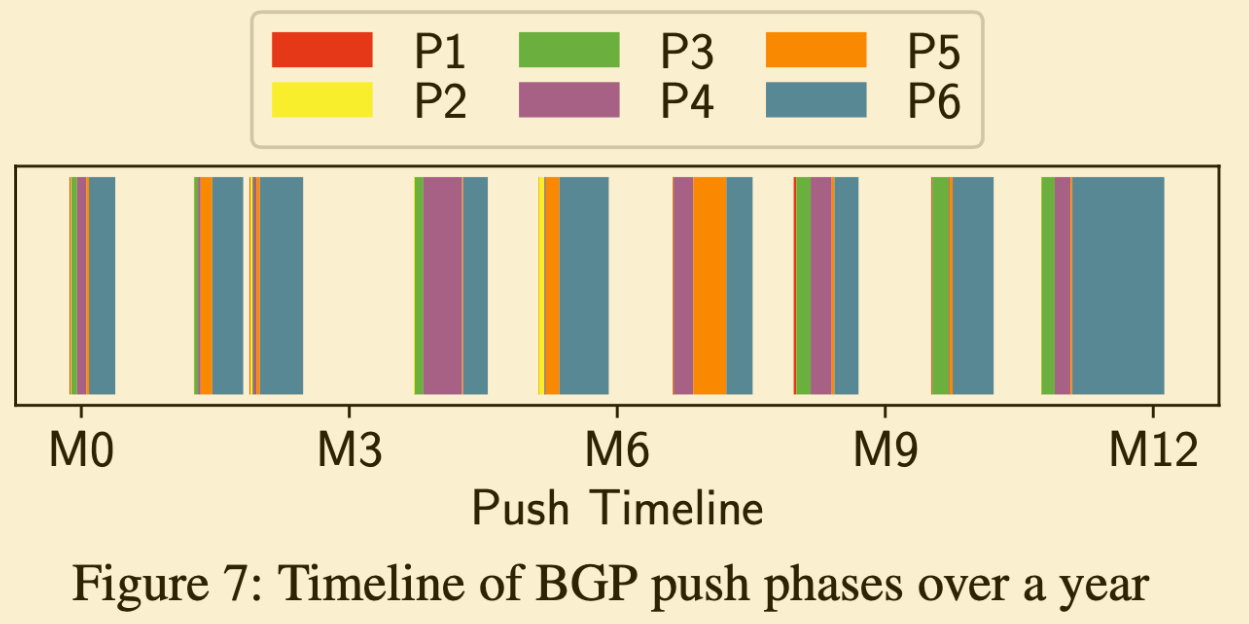
出典: 実績として、12ヶ月でBGPエージェントを9回デプロイした。平均して1度のデプロイに2~3週間かかった。
 出典:
出典: 6.3 SEVs
テストやデプロイの仕組みがあったとしても、スケールし続ける状況、他のサービスとの連携、ヒューマンエラーなどに起因する事故は避けられない。例として、あるTierへの変更と別のTierへの変更が互いに依存している状況で、想定していない順番でデプロイしたことでブラックホールを作ってしまった。また別の例として、BGP実装の最大Prefix数のカウンタにバグがあり、SLA違反を引き起こしてしまった。
おわり!