はじめに
The eXpress data path: fast programmable packet processing in the operating system kernel 1 を読んだ。 この文章はほとんどこの論文をもとに書いたが、一部ニュース記事を引用している。
eBPF/XDPが流行っているということは、BCC、bpftrace、Facebook Katran、Cloudflare Gatebot などeBPF/XDPを使うプロジェクトのGithub Star数から感じ取れる。 eBPF/XDPには、特殊なハードウェア・ソフトウェアに依存せず、 カーネルの仕掛けとして高速パケット処理を実現できるという強力なメリットがある。 一方であまり弱点を主張するような記事は見当たらないので、実際のところどうなのか感触を知りたい。
XDPを使うとNICデバイスドライバのコンテキストで、eBPF Verifilerの制約はありつつも、 比較的自由にパケット処理を実現できる。 また、成熟したLinuxのネットワークスタックと共存しつつ、1コアで24Mppsという高速なパケット処理を実現できる。 XDPプログラムは、eBPFの制約のもとC言語で記述することができ、clangでELFバイナリにコンパイルする。
XDPの競合としてカーネルバイパスなDPDKがある。両者の特徴は以下のとおり。
DPDK:
- カーネルバイパスによってコンテキストスイッチを避け高速化を図る
- コアを専有する(特定のコアでCPU 100%に張り付かせてポーリング)
- スループットとレイテンシどちらの観点で見てもDPDKのほうが優れている
- ネットワークスタックを再実装する必要がある
XDP:
- 専用コアが不要(電力面などで有利)
- 容易にロード・アンロードできる
- 名前空間などカーネルの機能に強く依存するコンテナ環境の普及で、XDPの重要度が増しているように感じる
- やはりカーネルネットワークスタックと共存できるというメリットが強い
アーキテクチャ
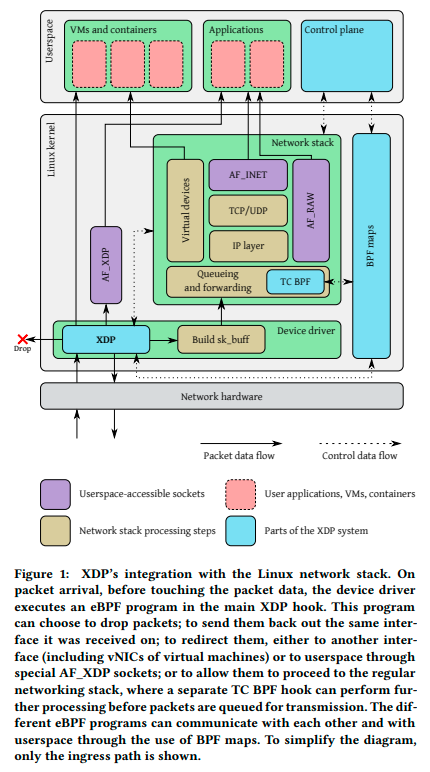
パケット着信のたびに、デバイスドライバのフックポイントでXDPプログラムが実行される。
このフックポイントは、デバイスドライバの処理の中でも初期に位置する(sk_buff の割り当て前)。
XDPプログラムは、ヘッダのパース、eBPFマップの読み書き、ヘルパ関数(FIBのルックアップなど)の呼び出しを経て、
最終的にパケットをどこに送り出すか決定する。
送り先については、XDPプログラムの終了コードで制御することができ、
ドロップさせる、同インターフェイスに送り返す、他インターフェイスに転送する、AF_XDPとしてユーザプログラムに送る、
通常のネットワークスタックに送る、から選択する。
2つ以上のXDPプログラムを同インターフェイスに紐付けたい場合には tail call として処理を引き渡すことができる。 外部のシステムとデータのやり取りをするために、eBPF Mapが用意されている。 eBPF Verifilerが厳しくチェックしているので、必ずeBPF Mapを使うことになりそうだ。
出典:The eXpress data path: fast programmable packet processing in the operating system kernel
動かしてみた
Linuxソースツリーには、XDPのサンプルコードが含まれている。
UDPパケットを受信したら、MACアドレスのsrc/dstをスワップして、同インターフェイスに送り返すといった内容になっている。
カーネルスペースで動作するXDPプログラム samples/bpf/xdp2_kern.c と、そのローダー samples/bpf/xdp1_user.c からなる。
# kernel 4.18.0
cd linux
# コンパイル
make samples/bpf/
# XDPプログラムのロード
sudo ./samples/bpf/xdp2 -S <interface>
# eBPF命令
bpftool prog dump xlated id $(sudo bpftool prog list | grep -oP "^[0-9]*")
# JIT後のx86_64命令
bpftool prog dump jit id $(sudo bpftool prog list | grep -oP "^[0-9]*")
性能評価
6コアのIntel Xeon E5-1650、Mellanox ConnectX-5 100G x2port、Linux 4.18環境で評価。 より詳細な評価環境についても公開されている 2 。
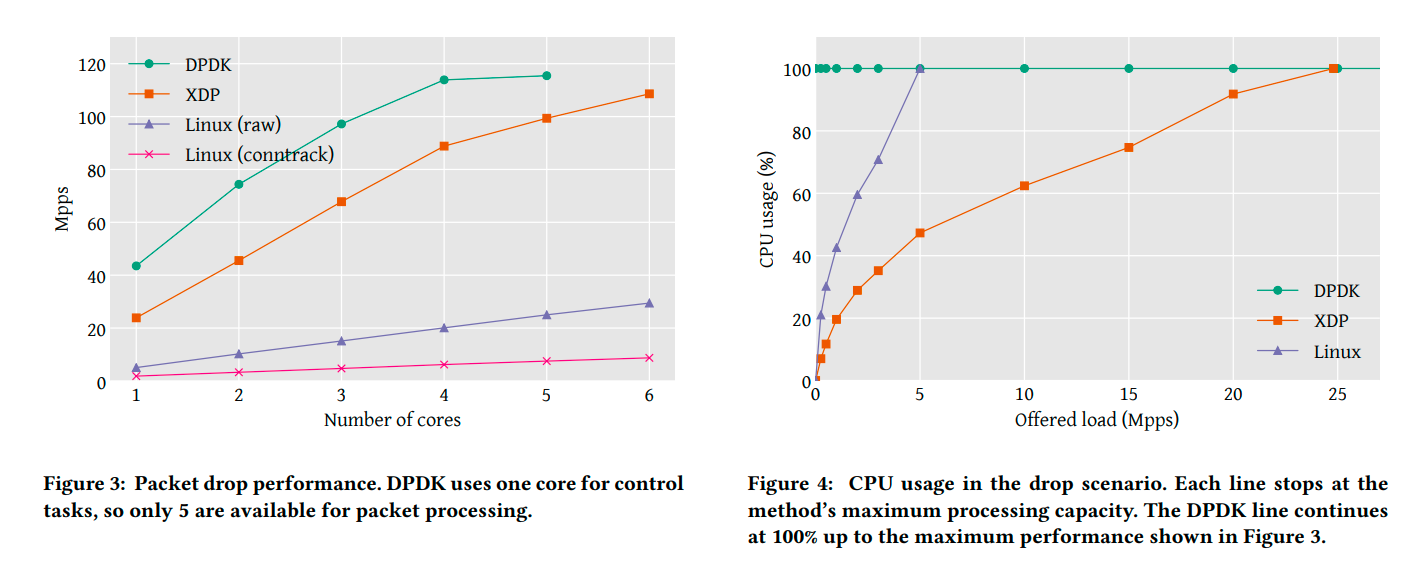
まず、パケットドロップ時の帯域について。コア数でスケールし、最終的にPCIバスの上限 115 Mpps で頭打ちする。 比較対象として挙がっているLinux(raw)はiptables、Linux(conntrack)はconntrackで実装したもの。
続いて、パケットドロップ時のCPU利用について。 DPDKは100%張り付く設計になっている。XDPは、トラフィックが少ない状況で割り込み処理のオーバヘッドが支配的になる。 結果、0 ~ 3 Mpps くらいの比較的トラフィックが少ない状況において傾きが大きく、それ以降徐々に傾きが緩やかになる。
パケットフォワーディングでは、同NICに送り返すか否かによる差が大きい。 MACアドレスのスワップ処理が発生するため、性能上限はパケットドロップの場合を下回る。 この場合でも最大性能はPCI バスの制約で頭打ちする。 Same NICとDifferent NICの性能差は、パケットバッファが受信NICに紐付けられる点から説明できる。
最後に遅延について見てみると、DPDKのほうが少なくトラフィック量にも依存せず安定している。 XDPでは、トラフィックが少ない状況で、割り込み処理にかかる時間が全体を支配するような状況になってしまう。
DPDKとXDPの性能差はどこから来るのか。 1コアでのパケットドロップレートは、XDPで24Mpps(41.6ns / packet)、DPDKで43.5Mpps(22.9ns / packet)。 1パケットあたり18.7nsの差分がある。 1回の関数呼び出しがおおよそ1.3nsであり、mlx5 driverでは10回の関数呼び出しがあるので、ここで13nsかかってしまう。 関数呼び出しを減らすことで、24Mppsから29Mppsまで高速化できる。他にも最適化の余地は残っている。
出典:The eXpress data path: fast programmable packet processing in the operating system kernel
ユースケース
3つのユースケースを紹介する。
1つ目はソフトウェアルータ。
静的に1ルートだけを入れたsingle routeと752,138ルートを入れた full route の2つのシナリオで、
XDPとLinuxで性能比較をした。結果、2~3倍XDPのほうがスループットが良い。
Linuxは full-featured なルーティングテーブルを持っており、これを XDP から参照できる。
ヘルパ関数 bpf_fib_lookup は、呼び出し結果として、ネクストホップに繋がるインターフェイスとそのMACアドレスが返ってくるので、使い勝手が良い 3 。
2つ目はDoS Mitigation。 ハイパーバイザ上でDos MitigationのためにXDPを実施する。論文中のグラフは1コアのもの。 20Mpps の DoS であれば、耐えられるようだ。 Cloudflare社のGatebotで使われていてニュース 4 になっていた。 このニュースではXDPというよりも人を介さない自動検知・対処のしくみを作ったことで注目されている(脱線するがこれは凄い!)。
3つ目はL4 Loadbalancer。Facebook Katranが例に挙げられていた。 XDPは、クライアントから受け取ったパケットに対するハッシュ計算とカプセル化を担当している。
今後
eBPFの制約緩和、ドライバのXDPサポート、QoS(Quality of Service)サポート、AQM(Active Queue Management)サポート、 Statefull対応などがTODOとしてあるようだ。 また、Cilium、Open vSwitch等ミドルウェアとの連携も進むだろう。 GKE 5 でも Cilium ベースのデータプレーンが使われているようだ。
補足
XDPプログラムを開発するには、以下の手順を踏む。
- 制限つきのC言語でXDPプログラムを記述
- clangでeBPFバイトコードへ変換し、ELFバイナリとして吐き出す
- libbpf、bpftool、iproute2などでカーネルへロードする。どれを使うかによって、セクション命名規則が違う
eBPFバイトコードを見ると、64bitレジスタが11個使われており、実行時にハードウェアレジスタ(x86-64ならRAXやRCXなど)にマッピングされる。
bpftool prog dump xlated や bpftool prog dump jit で命令列を確認できる。