Introduction
I read “The eXpress data path: fast programmable packet processing in the operating system kernel” 1. This article is mostly based on this paper, with some references to news articles.
The popularity of eBPF/XDP can be felt from the GitHub star counts of projects using eBPF/XDP, such as BCC, bpftrace, Facebook Katran, and Cloudflare Gatebot. eBPF/XDP has a powerful advantage: it can achieve high-speed packet processing as a kernel mechanism without depending on special hardware or software. On the other hand, there aren’t many articles highlighting weaknesses, so I wanted to get a feel for how it actually works.
With XDP, you can implement packet processing relatively freely in the context of the NIC device driver, albeit with the constraints of the eBPF Verifier. Moreover, while coexisting with the mature Linux network stack, it can achieve high-speed packet processing of 24Mpps per core. XDP programs can be written in C language under eBPF constraints and compiled into ELF binaries with clang.
DPDK is a competing kernel-bypass solution. The characteristics of both are as follows:
DPDK:
- Achieves speed by avoiding context switches through kernel bypass
- Monopolizes cores (polls by pinning a specific core to 100% CPU)
- Superior to XDP from both throughput and latency perspectives
- Requires reimplementation of the network stack
XDP:
- No dedicated core required (advantageous in terms of power consumption)
- Can be easily loaded and unloaded
- With the spread of container environments that heavily depend on kernel features like namespaces, XDP’s importance seems to be increasing
- The strong advantage of being able to coexist with the kernel network stack is evident
Architecture
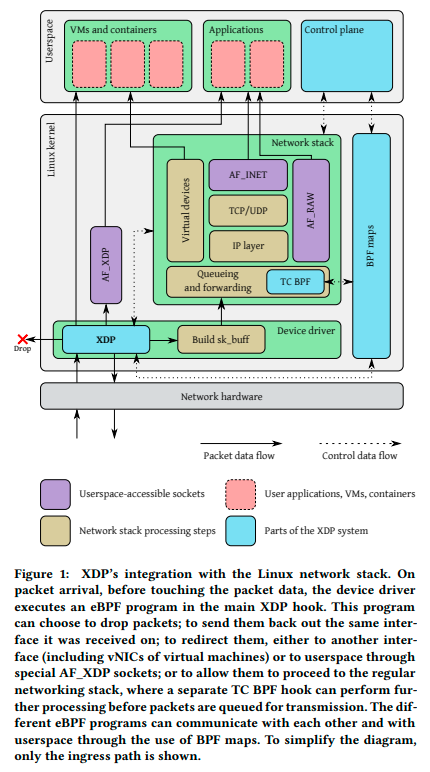
Each time a packet arrives, the XDP program is executed at the device driver’s hook point.
This hook point is positioned early in the device driver processing (before sk_buff allocation).
The XDP program parses headers, reads/writes eBPF maps, calls helper functions (such as FIB lookups), and finally determines where to send the packet.
The destination is controlled by the XDP program’s exit code:
drop, send back to the same interface, forward to another interface, send to user program as AF_XDP, or send to the normal network stack.
When you want to attach two or more XDP programs to the same interface, you can pass processing as a tail call. eBPF Maps are provided for exchanging data with external systems. The eBPF Verifier checks strictly, so it’s likely you’ll need to use eBPF Maps.
Source: The eXpress data path: fast programmable packet processing in the operating system kernel
Trying It Out
The Linux source tree contains XDP sample code.
When a UDP packet is received, it swaps the MAC address src/dst and sends it back to the same interface.
It consists of an XDP program running in kernel space samples/bpf/xdp2_kern.c and its loader samples/bpf/xdp1_user.c.
# kernel 4.18.0
cd linux
# Compile
make samples/bpf/
# Load XDP program
sudo ./samples/bpf/xdp2 -S <interface>
# eBPF instructions
bpftool prog dump xlated id $(sudo bpftool prog list | grep -oP "^[0-9]*")
# JIT x86_64 instructions
bpftool prog dump jit id $(sudo bpftool prog list | grep -oP "^[0-9]*")
Performance Evaluation
Evaluated on 6-core Intel Xeon E5-1650, Mellanox ConnectX-5 100G x2 ports, Linux 4.18 environment. More detailed evaluation environment is also published 2.
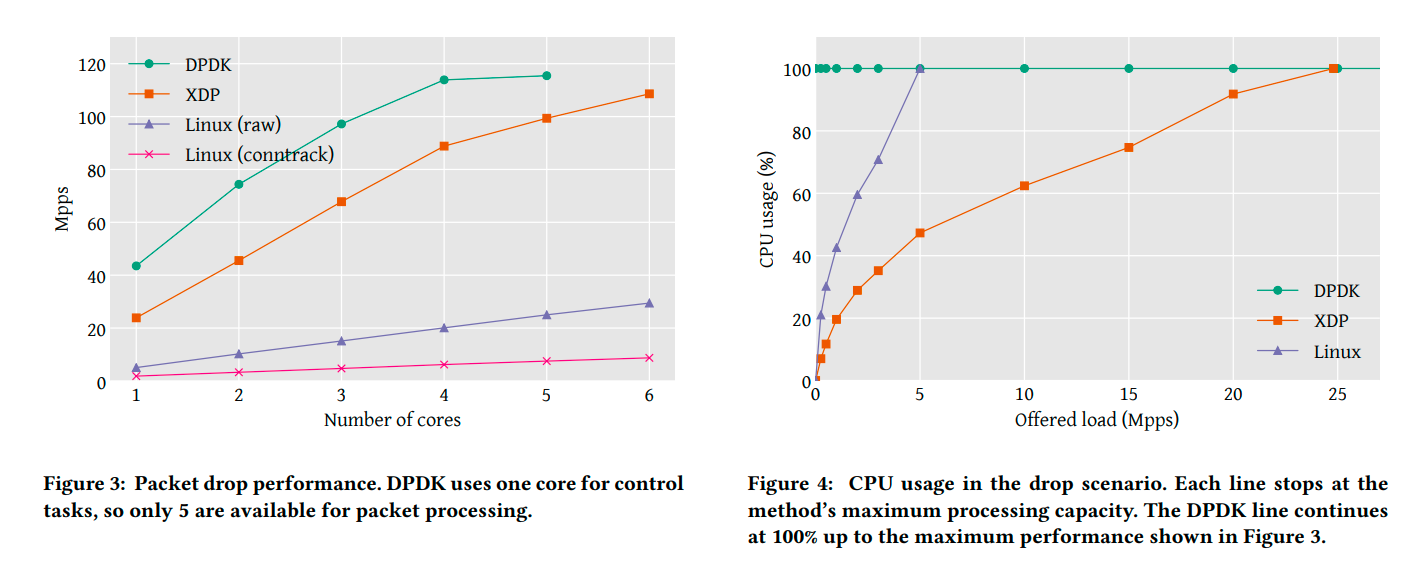
First, regarding bandwidth when dropping packets. It scales with the number of cores and eventually hits the PCI bus limit of 115 Mpps. Linux (raw) shown as a comparison is implemented with iptables, Linux (conntrack) is implemented with conntrack.
Next, regarding CPU utilization when dropping packets. DPDK is designed to pin at 100%. For XDP, interrupt processing overhead becomes dominant in low traffic situations. As a result, the slope is steep in relatively low traffic situations around 0 ~ 3 Mpps, and then gradually becomes gentler.
In packet forwarding, there’s a significant difference depending on whether packets are sent back to the same NIC or not. Since MAC address swapping processing occurs, the performance limit is lower than the packet drop case. Even in this case, maximum performance is limited by PCI bus constraints. The performance difference between Same NIC and Different NIC can be explained by the fact that packet buffers are tied to the receiving NIC.
Finally, looking at latency, DPDK is lower and stable regardless of traffic volume. For XDP, in low traffic situations, the time spent on interrupt processing dominates the overall time.
Where does the performance difference between DPDK and XDP come from? Packet drop rate per core is 24Mpps (41.6ns / packet) for XDP and 43.5Mpps (22.9ns / packet) for DPDK. There’s an 18.7ns difference per packet. One function call takes approximately 1.3ns, and the mlx5 driver makes 10 function calls, accounting for 13ns. By reducing function calls, performance can be improved from 24Mpps to 29Mpps. There’s still room for other optimizations.
Source: The eXpress data path: fast programmable packet processing in the operating system kernel
Use Cases
Three use cases are introduced.
The first is a software router.
Performance comparison between XDP and Linux was done in two scenarios: single route with only 1 statically entered route, and full route with 752,138 routes.
The result shows that XDP has 2-3 times better throughput.
Linux has a full-featured routing table, which can be referenced from XDP.
The helper function bpf_fib_lookup returns the interface and its MAC address connected to the next hop, making it convenient to use 3.
The second is DoS Mitigation. Performing XDP on a hypervisor for DoS mitigation. The graph in the paper shows single core performance. It appears capable of withstanding 20Mpps DoS attacks. It’s being used by Cloudflare’s Gatebot and was featured in the news 4. This news drew attention not so much for XDP, but for creating an automated detection and response mechanism without human intervention (a bit off-topic, but this is amazing!).
The third is L4 Load balancer. Facebook Katran was given as an example. XDP handles hash calculation and encapsulation for packets received from clients.
Future
TODOs include relaxing eBPF constraints, driver XDP support, QoS (Quality of Service) support, AQM (Active Queue Management) support, and Stateful support. Also, integration with middleware such as Cilium and Open vSwitch will progress. GKE 5 also seems to be using a Cilium-based data plane.
Supplement
To develop XDP programs, follow these steps:
- Write XDP program in restricted C language
- Convert to eBPF bytecode with clang and output as ELF binary
- Load into kernel with libbpf, bpftool, iproute2, etc. Section naming conventions differ depending on which one you use
Looking at eBPF bytecode, 11 64-bit registers are used, which are mapped to hardware registers (such as RAX or RCX on x86-64) at runtime.
You can check instruction sequences with bpftool prog dump xlated or bpftool prog dump jit.